ConQueR: Query Contrast Voxel-DETR for 3D Object Detection
Abstract
DETRs usually adopt a larger number of queries than GTs (e.g., 300 queries v.s. 40 objects in Waymo) in a scene, which inevitably incur many false positives during inference. In this paper, we propose a simple yet effective sparse 3D detector, named Query Contrast Voxel-DETR (ConQueR), to eliminate the challenging false positives, and achieve more accurate and sparser predictions. We observe that most false positives are highly overlapping in local regions, caused by the lack of explicit supervision to discriminate locally similar queries. We thus propose a Query Contrast mechanism to explicitly enhance queries towards their best-matched GTs over all unmatched query predictions through a contrastive loss. ConQueR closes the gap of sparse and dense 3D detectors, and reduces up to 60% false positives. Our single-frame ConQueR achieves new state-of-the-art (sota) 71.6 mAPH/L2 on the challenging Waymo Open Dataset validation set, outperforming previous sota methods (e.g., PV-RCNN++) by over 2.0 mAPH/L2.
Benjin ZHU1, Zhe WANG1, Shaoshuai SHI2, Hang XU3, Lanqing HONG3, Hongsheng LI1
1 MMLab, The Chinese University of Hong Kong 2 Max Planck Institute for Informatics 3 Huawei Noah's Ark Lab
Motivation
To achieve direct sparse predictions, DETRs usually adopt a set of object queries, and resort to the one-to-one Hungarian Matching to assign ground-truths (GTs) to object queries. However, to guarantee a high recall rate, those detectors need to impose much more queries than the actual number of objects in a scene. For example, recent works select top-300 scored query predictions to cover only ∼40 objects in each scene of Waymo Open Dataset (WOD). Objects are generally small and densely populated in autonomous driving scenes, while 3D DETRs adopt the same fixed top-N scored predictions as 2D DETRs, and lack a mechanism to handle such small and dense objects. Consequently, they tend to generate densely overlapped false positives (in the red-dashed circle), harming both the accuracy and sparsity of final predictions.
Method
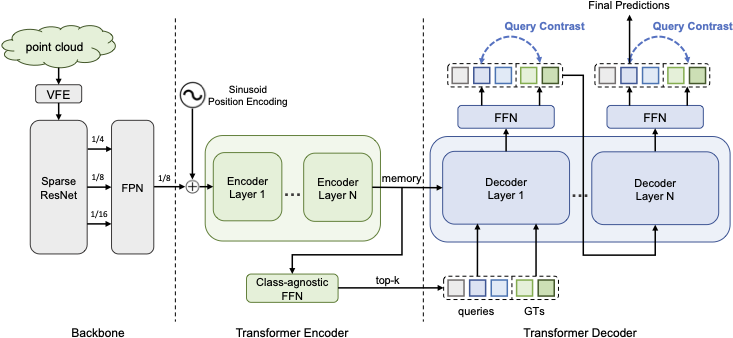
The proposed ConQueR consists of a 3D Sparse ResNet-FPN backbone to extract dense BEV features, and a transformer encoder-decoder architecture with one-to-one matching. Top-k scored object proposals from a class-agnostic FFN form the object queries to input to the transformer decoder. During training, GTs (noised) are concatenated with object queries to input to the transformer decoder to obtain uniAed embeddings, which are then used for Query Contrast at each decoder layer. During inference, Top- scored predictions from the last decoder layer are kept as Anal sparse predictions.
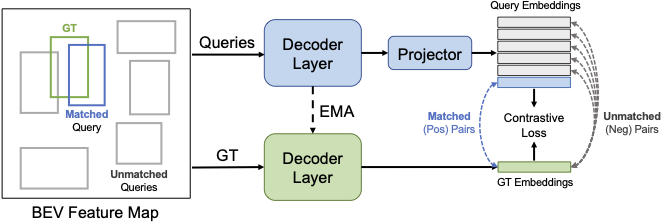
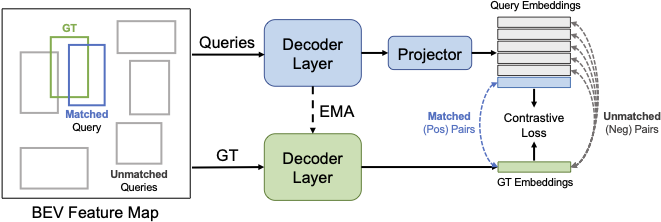
Query Contrast
Given the GT (green), Hungarian Matching gives its best matched (blue) and all other unmatched (gray) object queries. Query embeddings are projected by an extra MLP to align with GT embeddings. The contrastive loss is applied to all positive and negative GT-query pairs based on their feature similarities.
Results
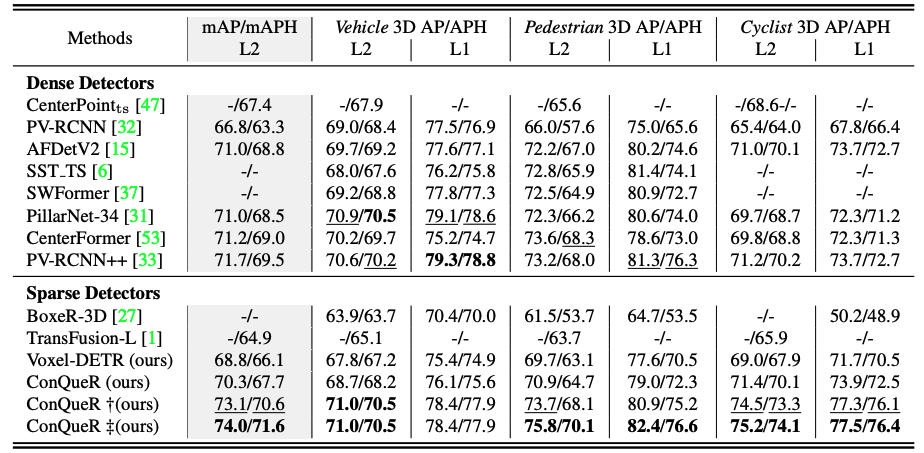
As shown in Table 1, our sparse detector ConQueR sets new records on all categories of the WOD validation set. ConQueR with direct sparse predictions (the second-last entry) achieves1.0 mAPH/L2 higher than the previous best single-frame model PV-RCNN++, and is over 3.0 mAPH/L2 higher than the popular anchor-free CenterPoint. Notably, ConQueR demonstrates overwhelming performance on pedestrians and cyclists, outperforming previous best methods by 2.0 APH/L2, which shows the effectiveness of our Query Contrast strategy especially for densely populated categories. Moreover, ConQueR surpasses previous best sparse detectors TransFusion-L by 6.0 mAPH/L2, closing the performance gap between sparse and dense 3D detectors. When compared with our baseline Voxel-DETR, the proposed Query Contrast mechanismbrings over 1.6 mAPH/L2 without any extra inference cost.
Citation
@inproceedings{zhu2023conquer,
title={ConQueR: Query contrast voxel-detr for 3d object detection},
author={Zhu, Benjin and Wang, Zhe and Shi, Shaoshuai and Xu, Hang and Hong, Lanqing and Li, Hongsheng},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={9296--9305},
year={2023}
}