Beginner's guide to CUDA C++ Programming
Quick start tutorial for CUDA beginners
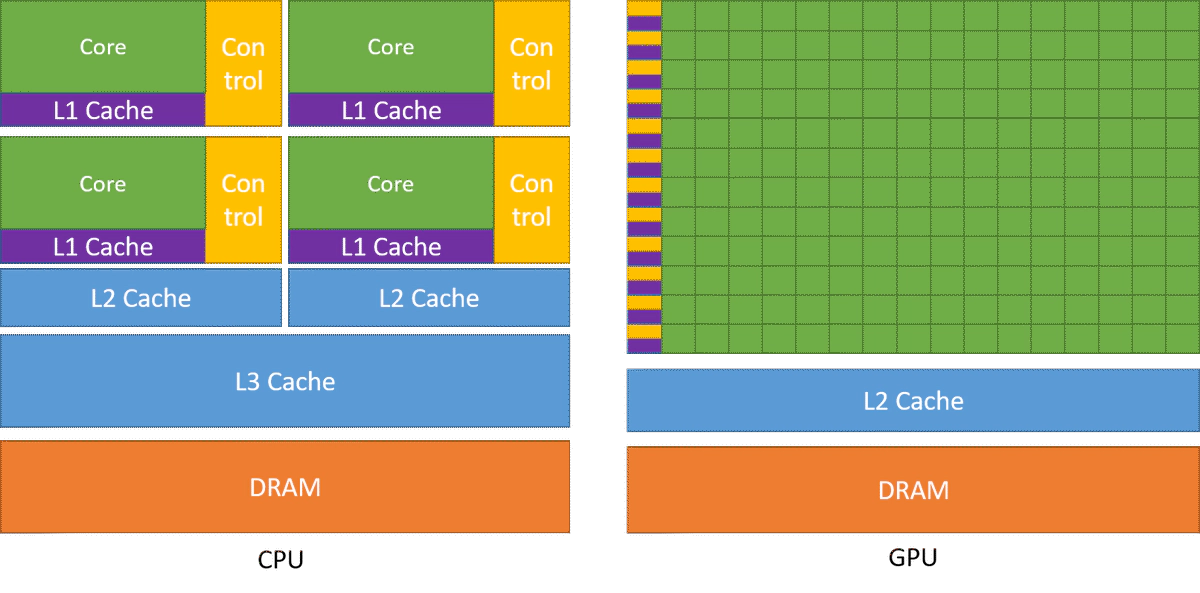 Image credit: NVIDIA
Image credit: NVIDIATerminology
host– refers to normal CPU-based hardware and normal programs that run in that environmentdevice– refers to a specific GPU that CUDA programs run in. A single host can support multiple devices.kernel– a function that resides on the device that can be invoked from the host code.
Physical GPU layout
The CUDA-enabled GPU processor has the following physical structure:
- the chip - the whole processor of the GPU. Some GPUs have two of them.
- streamming multiprocessor (SM) - each chip contains up to ~100 SMs, depending on a model. Each SM operates nearly independently from another, using only global memory to communicate to each other.
- CUDA core - a single scalar compute unit of a SM. Their precise number depends on the architecture. Each core can handle a few threads executed concurrently in a quick succession (similar to hyperthreading in CPU).
In addition, each SM features one or more warp schedulers. Each scheduler dispatches a single instruction to several CUDA cores. This effectively causes the SM to operate in 32-wide SIMD mode.
CUDA Execution Model
The physical structure of the GPU has direct influence on how kernels are executed on the device, and how one programs them in CUDA. Kernel is invoked with a call configuration which specifies how many parallel threads are spawned.
- the grid - represents all threads that are spawned upon kernel call. It is specified as a one or two dimentional set of blocks. The maximum size for any dimension is 65535!
- the block - is a semi-independent set of threads. Each block is assigned to a single SM. As such, blocks can communicate only through global memory. Blocks are not synchronized in any way. If there are too many blocks, some may execute sequentially after others. On the other hand, if resources permit, more than one block may run on the same SM, but the programmer cannot benefit from that happening (except for the obvious performance boost). A general guidline is that a block should consist of at least 192 threads in order to hide memory access latency. Therefore, 256, and 512 threads are common and practical numbers. It’s best to think of a thread block as a 3-d block of threads.
- the thread - a scalar sequence of instructions executed by a single CUDA core. Threads are ’lightweight’ with minimal context, allowing the hardware to quickly swap them in and out. Because of their number, CUDA threads operate with a few registers assigned to them, and very short stack (preferably none at all!). For that reason, CUDA compiler prefers to inline all function calls to flatten the kernel so that it contains only static jumps and loops. Function ponter calls, and virtual method calls, while supported in most newer devices, usually incur a major performance penality.
- Each thread is identified by a block index
blockIdxand thread index within the blockthreadIdx. These numbers can be checked at any time by any running thread and is the only way of distinguishing one thread from another.
In addition, threads are organized into warps, each containing exactly 32 threads. Threads within a single warp execute in a perfect sync, in SIMD fahsion. Threads from different warps, but within the same block can execute in any order, but can be forced to synchronize by the programmer. Threads from different blocks cannot be synchronized or interact directly in any way.
Memory Organisation
In normal CPU programming the memory organization is usually hidden from the programmer. Typical programs act as if there was just RAM. All memory operations, such as managing registers, using L1- L2- L3- caching, swapping to disk, etc. is handled by the compiler, operating system or hardware itself.
This is not the case with CUDA. While newer GPU models partially hide the burden, e.g. through the Unified Memory in CUDA 6, it is still worth understanding the organization for performance reasons. The basic CUDA memory structure is as follows:
- Host memory – the regular RAM. Mostly used by the host code, but newer GPU models may access it as well. When a kernel access the host memory, the GPU must communicate with the motherboard, usually through the PCIe connector and as such it is relatively slow.
- Device memory / Global memory – the main off-chip memory of the GPU, available to all threads.
- Shared memory - located in each SM allows for much quicker access than global. Shared memory is private to each block. Threads within a single block can use it for communication.
- Registers - fastest, private, unaddressable memory of each thread. In general these cannot be used for communication, but a few intrinsic functions allows to shuffle their contents within a warp.
- Local memory - private memory of each thread that is addressable. This is used for register spills, and local arrays with variable indexing. Physically, they reside in global memory.
- Texture memory, Constant memory - a part of global memory that is marked as immutable for the kernel. This allows the GPU to use special-purpose caches.
- L2 cache – on-chip, available to all threads. Given the amount of threads, the expected lifetime of each cache line is much lower than on CPU. It is mostly used aid misaligned and partially-random memory access patterns.
- L1 cache – located in the same space as shared memory. Again, the amount is rather small, given the number of threads using it, so do not expect data to stay there for long. L1 caching can be disabled.
Example
Memory Allocation
float *h_dataA, *h_dataB, *h_resultC;
float *d_dataA, *d_dataB, *d_resultC;
h_dataA = (float *)malloc(sizeof(float) * MAX_DATA_SIZE);
h_dataB = (float *)malloc(sizeof(float) * MAX_DATA_SIZE);
h_resultC = (float *)malloc(sizeof(float) * MAX_DATA_SIZE);
CUDA_SAFE_CALL( cudaMalloc( (void **)&d_dataA, sizeof(float) * MAX_DATA_SIZE) );
CUDA_SAFE_CALL( cudaMalloc( (void **)&d_dataB, sizeof(float) * MAX_DATA_SIZE) );
comments: The
cudaMallocfunction requires a pointer to a pointer (i.e., void ) because it modifies the pointer to point to the newly allocated memory on the device. When you call cudaMalloc, it allocates memory on the device (GPU) and then sets your pointer (d_dataA, d_dataB, d_resultC, etc.) to point to this new memory location.
In C, all arguments are passed by value, meaning that the function gets a copy of the argument, not the original variable itself. If you passed a single-level pointer (like d_resultC directly), cudaMalloc would only modify its local copy of the pointer, not the d_resultC pointer in your code. By passing the address of d_resultC (i.e., a pointer to the pointer), cudaMalloc can modify the original d_resultC to point to the newly allocated memory on the device.
Kernel Function
__global__ void multiplyNumbersGPU(float *pDataA, float *pDataB, float *pResult)
{
// We already set it to 256 threads per block, with 128 thread blocks per grid row.
int tid = (blockIdx.y * 128 * 256) + blockIdx.x * 256 + threadIdx.x; // This gives every thread a unique ID.
pResult[tid] = sqrt(pDataA[tid] * pDataB[tid] / 12.34567) * sin(pDataA[tid]);
}
__global__ indicates that this function may be called from either the host PC or the CUDA device. Each thread runs the same code, so the only way for them to differentiate themselves from the other threads is to use their threadIdx, and their blockIdx.
BlockIdx.y * 128 * 256 is equal to the number of threads in all rows of the grid above the current thread’s position. The blockIdx.x * 256 is equal to the number of threads in all columns of the current grid-row before the curren’t thread’s block. Finally, threadIdx.x is equal to the number of threads before the current thread in the current block (remember that the threads winith a thread block are organized linearly in this tutorial, so threadIdx.y isn’t needed).
Thread Communication
Generally, threads may only safely communicate with each other if and only if they exist within the same thread block. There are technically ways where two threads from different blocks can communicate with each other, but this is much more difficult, and much more prone to bugs within your program.
- Sharerd Memory: Threads within the same block have two main ways to communicate data with each other. The fastest way would be to use shared memory. When a block of threads starts executing, it runs on an SM, a multiprocessor unit inside the GPU. Each SM has a fairly small amount of shared memory associated with it, usually 16KB of memory. To make matters more difficult, often times, multiple thread blocks can run simultaneously on the same SM. For example, if each SM has 16KB of shared memory and there are 4 thread blocks running simultaneously on an SM, then the maximum amount of shared memory available to each thread block would be 16KB/4, or 4KB. So as you can see, if you only need the threads to share a small amount of data at any given time, using shared memory is by far the fastest and most convenient way to do it.
- Global Memory: However, if your program is using too much shared memory to store data, or your threads simply need to share too much data at once, then it is possible that the shared memory is not big enough to accommodate all the data that needs to be shared among the threads. In such a situation, threads always have the option of writing to and reading from global memory. Global memory is much slower than accessing shared memory, however, global memory is much larger.
Declaring shared arrays
// Declare arrays to be in shared memory.
// 256 elements * (4 bytes / element) * 3 = 3KB.
__shared__ float min[256];
__shared__ float max[256];
__shared__ float avg[256];
__shared__ places a variable into shared memory for each respective thread block.
Value reduction
int nTotalThreads = blockDim.x; // Total number of active threads
while(nTotalThreads > 1)
{
int halfPoint = (nTotalThreads >> 1); // divide by two
// only the first half of the threads will be active.
if (threadIdx.x < halfPoint)
{
// Get the shared value stored by another thread
float temp = min[threadIdx.x + halfPoint];
if (temp < min[threadIdx.x]) min[threadIdx.x] = temp;
temp = max[threadIdx.x + halfPoint];
if (temp > max[threadIdx.x]) max[threadIdx.x] = temp;
// when calculating the average, sum and divide
avg[threadIdx.x] += avg[threadIdx.x + halfPoint];
avg[threadIdx.x] /= 2;
}
// This function acts as a barrier to all the threads in that particular thread block. No thread can continue past that block until all threads have reached that location.
__syncthreads();
nTotalThreads = (nTotalThreads >> 1); // divide by two.
}
Atomic operations
An atomic operation is capable of reading, modifying, and writing a value back to memory without the interference of any other threads, which guarentees that a race condition won’t occur. Atomic operations in CUDA generally work for both shared memory and global memory. Atomic operations in shared memory are generally used to prevent race conditions between different threads within the same thread block. Atomic operations in global memory are used to prevent race conditions between two different threads regaurdless of which thread block they are in.
int atomicAdd(int* address, int val);
This atomicAdd function can be called within a kernel. When a thread executes this operation, a memory address is read, has the value of ‘val’ added to it, and the result is written back to memory.
As mentioned before, shared memory is much faster than global memory, so atomic operations in shared memory tend to complete faster than atomic operations in global memory. While atomic operations are often necessary in some algorithms, it is important to minimize their usage when possible, especially with global memory accesses.
Also beware of serialization. If two threads perform an atomic operation at the same memory address at the same time, those operations will be serialized. The order in which the operations complete is undefined, which is fine, but the serialization can be quite costly.
Note: atomicAdd support double since 6.X. Atomic operations generally require global memory accesses, which take hundreds of clock cycles. Therefore, it is absolutely vital that you limit the number of atomic operations as much as you possibly can. While atomic operations are supported in shared memory in some of the more recent CUDA devices, many algorithms will make use of atomic operations to facilitate communication between separate thread blocks, which means global memory accesses. Just remember, atomic operations can either be your best friend, or your worst enemy.
Image Processing Example
// This code originates from supercomputingblog.com
// This code is provided as is without any warranty of any kind
// Feel free to use this code however you'd like, as long as
// due credit is given, and this header remains intact.
void __global__ PaintCu(int width, int height, int stride, unsigned int *pRawBitmapOrig, unsigned int *pBitmapCopy, int radius, int nBins)
{
// This CUDA kernel effectively transforms an image into an image that looks like it's been painted.
// Each thread will calculate exactly 1 final pixel
// The processing of each pixel requires many computations, and the use of 4 kilobytes of memory.
// This code will work well on fermi archetecture and beyond due to the cache structure of the GPU
int i = blockIdx.y * blockDim.y + threadIdx.y;
int j = blockIdx.x * blockDim.x + threadIdx.x;
// Test to see if we're testing a valid pixel
if (i >= height || j >= width) return; // Don't bother doing the calculation. We're not in a valid pixel location
#define C_MAX_INTENSITIES 256 // 8 bits per color, 256 intensities is fine.
int intensityCount[C_MAX_INTENSITIES];
int avgR[C_MAX_INTENSITIES];
int avgG[C_MAX_INTENSITIES];
int avgB[C_MAX_INTENSITIES];
for (int k=0; k <= nBins; k++)
{
intensityCount[k] = 0;
avgR[k] = 0;
avgG[k] = 0;
avgB[k] = 0;
}
// we have a radius r
int maxIntensityCount = 0;
int maxIntensityCountIndex = 0;
for (int k=i-radius; k <= i+radius;k++)
{
if (k < 0 || k >= height) continue;
for (int l=j-radius; l <= j+radius; l++)
{
if (l < 0 || l >= width) continue;
int curPixel = pBitmapCopy[k*stride/4 + l];
int r = ((curPixel & 0x00ff0000) >> 16);
int g = ((curPixel & 0x0000ff00) >> 8);
int b = ((curPixel & 0x000000ff) >> 0);
int curIntensity = (int)((float)((r+g+b)/3*nBins)/255.0f);
intensityCount[curIntensity]++;
if (intensityCount[curIntensity] > maxIntensityCount)
{
maxIntensityCount = intensityCount[curIntensity];
maxIntensityCountIndex = curIntensity;
}
avgR[curIntensity] += r;
avgG[curIntensity] += g;
avgB[curIntensity] += b;
}
}
int finalR = avgR[maxIntensityCountIndex] / maxIntensityCount;
int finalG = avgG[maxIntensityCountIndex] / maxIntensityCount;
int finalB = avgB[maxIntensityCountIndex] / maxIntensityCount;
pRawBitmapOrig[i*stride/4 + j] = 0xff000000 | ((finalR << 16) + (finalG << 8) + finalB);
}
CPU code
#pragma omp parallel
for (int i=0; i < height; i++)
{
#define C_MAX_INTENSITIES 256 // 8 bits per color, 256 intensities is fine.
int intensityCount[C_MAX_INTENSITIES];
int avgR[C_MAX_INTENSITIES];
int avgG[C_MAX_INTENSITIES];
int avgB[C_MAX_INTENSITIES];
for (int j=0; j < width; j++)
{
// reset to zero
for (int k=0; k <= nBins; k++)
{
intensityCount[k] = 0;
avgR[k] = 0;
avgG[k] = 0;
avgB[k] = 0;
}
// we have a radius r
int maxIntensityCount = 0;
int maxIntensityCountIndex = 0;
for (int k=i-radius; k <= i+radius;k++)
{
if (k < 0 || k >= height) continue;
for (int l=j-radius; l <= j+radius; l++)
{
if (l < 0 || l >= width) continue;
int curPixel = pBitmapCopy[k*bitmapData.Stride/4 + l];
int r = ((curPixel & 0x00ff0000) >> 16);
int g = ((curPixel & 0x0000ff00) >> 8);
int b = ((curPixel & 0x000000ff) >> 0);
int curIntensity = (int)((float)((r+g+b)/3*nBins)/255.0f);
intensityCount[curIntensity]++;
if (intensityCount[curIntensity] > maxIntensityCount)
{
maxIntensityCount = intensityCount[curIntensity];
maxIntensityCountIndex = curIntensity;
}
avgR[curIntensity] += r;
avgG[curIntensity] += g;
avgB[curIntensity] += b;
}
}
int finalR = avgR[maxIntensityCountIndex] / maxIntensityCount;
int finalG = avgG[maxIntensityCountIndex] / maxIntensityCount;
int finalB = avgB[maxIntensityCountIndex] / maxIntensityCount;
pRawBitmapOrig[i*bitmapData.Stride/4 + j] = 0xff000000 | ((finalR << 16) + (finalG << 8) + finalB);
}
}