Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Requirement already satisfied: pytorch-pretrained-biggan in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (0.1.1)
Requirement already satisfied: torch>=0.4.1 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from pytorch-pretrained-biggan) (2.5.1)
Requirement already satisfied: numpy in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from pytorch-pretrained-biggan) (2.0.1)
Requirement already satisfied: boto3 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from pytorch-pretrained-biggan) (1.35.63)
Requirement already satisfied: requests in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from pytorch-pretrained-biggan) (2.32.3)
Requirement already satisfied: tqdm in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from pytorch-pretrained-biggan) (4.67.0)
Requirement already satisfied: filelock in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from torch>=0.4.1->pytorch-pretrained-biggan) (3.13.1)
Requirement already satisfied: typing-extensions>=4.8.0 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from torch>=0.4.1->pytorch-pretrained-biggan) (4.11.0)
Requirement already satisfied: setuptools in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from torch>=0.4.1->pytorch-pretrained-biggan) (75.1.0)
Requirement already satisfied: sympy==1.13.1 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from torch>=0.4.1->pytorch-pretrained-biggan) (1.13.1)
Requirement already satisfied: networkx in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from torch>=0.4.1->pytorch-pretrained-biggan) (3.2.1)
Requirement already satisfied: jinja2 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from torch>=0.4.1->pytorch-pretrained-biggan) (3.1.4)
Requirement already satisfied: fsspec in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from torch>=0.4.1->pytorch-pretrained-biggan) (2024.10.0)
Requirement already satisfied: mpmath<1.4,>=1.1.0 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from sympy==1.13.1->torch>=0.4.1->pytorch-pretrained-biggan) (1.3.0)
Requirement already satisfied: botocore<1.36.0,>=1.35.63 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from boto3->pytorch-pretrained-biggan) (1.35.63)
Requirement already satisfied: jmespath<2.0.0,>=0.7.1 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from boto3->pytorch-pretrained-biggan) (1.0.1)
Requirement already satisfied: s3transfer<0.11.0,>=0.10.0 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from boto3->pytorch-pretrained-biggan) (0.10.3)
Requirement already satisfied: charset-normalizer<4,>=2 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from requests->pytorch-pretrained-biggan) (3.3.2)
Requirement already satisfied: idna<4,>=2.5 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from requests->pytorch-pretrained-biggan) (3.7)
Requirement already satisfied: urllib3<3,>=1.21.1 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from requests->pytorch-pretrained-biggan) (2.2.3)
Requirement already satisfied: certifi>=2017.4.17 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from requests->pytorch-pretrained-biggan) (2024.8.30)
Requirement already satisfied: python-dateutil<3.0.0,>=2.1 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from botocore<1.36.0,>=1.35.63->boto3->pytorch-pretrained-biggan) (2.9.0.post0)
Requirement already satisfied: MarkupSafe>=2.0 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from jinja2->torch>=0.4.1->pytorch-pretrained-biggan) (2.1.3)
Requirement already satisfied: six>=1.5 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from python-dateutil<3.0.0,>=2.1->botocore<1.36.0,>=1.35.63->boto3->pytorch-pretrained-biggan) (1.16.0)
Note: you may need to restart the kernel to use updated packages.
pipinstallPillowlibsixel-python
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Requirement already satisfied: Pillow in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (11.0.0)
Requirement already satisfied: libsixel-python in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (0.5.0)
Note: you may need to restart the kernel to use updated packages.
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Requirement already satisfied: matplotlib in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (3.9.2)
Requirement already satisfied: tqdm in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (4.67.0)
Requirement already satisfied: contourpy>=1.0.1 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from matplotlib) (1.3.1)
Requirement already satisfied: cycler>=0.10 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from matplotlib) (0.12.1)
Requirement already satisfied: fonttools>=4.22.0 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from matplotlib) (4.55.0)
Requirement already satisfied: kiwisolver>=1.3.1 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from matplotlib) (1.4.7)
Requirement already satisfied: numpy>=1.23 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from matplotlib) (2.0.1)
Requirement already satisfied: packaging>=20.0 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from matplotlib) (24.2)
Requirement already satisfied: pillow>=8 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from matplotlib) (11.0.0)
Requirement already satisfied: pyparsing>=2.3.1 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from matplotlib) (3.2.0)
Requirement already satisfied: python-dateutil>=2.7 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from matplotlib) (2.9.0.post0)
Requirement already satisfied: six>=1.5 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from python-dateutil>=2.7->matplotlib) (1.16.0)
Note: you may need to restart the kernel to use updated packages.
pipinstallscipy
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Requirement already satisfied: scipy in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (1.14.1)
Requirement already satisfied: numpy<2.3,>=1.23.5 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from scipy) (2.0.1)
Note: you may need to restart the kernel to use updated packages.
!pip3installvibecheckdatatopsfromvibecheckimportDatatopsContentReviewContainerdefcontent_review(notebook_section:str):returnDatatopsContentReviewContainer("",# No text promptnotebook_section,{"url":"https://pmyvdlilci.execute-api.us-east-1.amazonaws.com/klab","name":"neuromatch_dl","user_key":"f379rz8y",},).render()feedback_prefix="W2D4_T1"
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Requirement already satisfied: vibecheck in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (0.0.5)
Requirement already satisfied: datatops in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (0.2.2)
Requirement already satisfied: ipython in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from vibecheck) (8.29.0)
Requirement already satisfied: ipywidgets in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from vibecheck) (8.1.5)
Requirement already satisfied: requests in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from datatops) (2.32.3)
Requirement already satisfied: flask in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from datatops) (3.1.0)
Requirement already satisfied: Werkzeug>=3.1 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from flask->datatops) (3.1.3)
Requirement already satisfied: Jinja2>=3.1.2 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from flask->datatops) (3.1.4)
Requirement already satisfied: itsdangerous>=2.2 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from flask->datatops) (2.2.0)
Requirement already satisfied: click>=8.1.3 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from flask->datatops) (8.1.7)
Requirement already satisfied: blinker>=1.9 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from flask->datatops) (1.9.0)
Requirement already satisfied: decorator in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from ipython->vibecheck) (5.1.1)
Requirement already satisfied: jedi>=0.16 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from ipython->vibecheck) (0.19.2)
Requirement already satisfied: matplotlib-inline in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from ipython->vibecheck) (0.1.7)
Requirement already satisfied: prompt-toolkit<3.1.0,>=3.0.41 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from ipython->vibecheck) (3.0.48)
Requirement already satisfied: pygments>=2.4.0 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from ipython->vibecheck) (2.18.0)
Requirement already satisfied: stack-data in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from ipython->vibecheck) (0.6.3)
Requirement already satisfied: traitlets>=5.13.0 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from ipython->vibecheck) (5.14.3)
Requirement already satisfied: pexpect>4.3 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from ipython->vibecheck) (4.9.0)
Requirement already satisfied: comm>=0.1.3 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from ipywidgets->vibecheck) (0.2.2)
Requirement already satisfied: widgetsnbextension~=4.0.12 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from ipywidgets->vibecheck) (4.0.13)
Requirement already satisfied: jupyterlab-widgets~=3.0.12 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from ipywidgets->vibecheck) (3.0.13)
Requirement already satisfied: charset-normalizer<4,>=2 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from requests->datatops) (3.3.2)
Requirement already satisfied: idna<4,>=2.5 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from requests->datatops) (3.7)
Requirement already satisfied: urllib3<3,>=1.21.1 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from requests->datatops) (2.2.3)
Requirement already satisfied: certifi>=2017.4.17 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from requests->datatops) (2024.8.30)
Requirement already satisfied: parso<0.9.0,>=0.8.4 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from jedi>=0.16->ipython->vibecheck) (0.8.4)
Requirement already satisfied: MarkupSafe>=2.0 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from Jinja2>=3.1.2->flask->datatops) (2.1.3)
Requirement already satisfied: ptyprocess>=0.5 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from pexpect>4.3->ipython->vibecheck) (0.7.0)
Requirement already satisfied: wcwidth in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from prompt-toolkit<3.1.0,>=3.0.41->ipython->vibecheck) (0.2.13)
Requirement already satisfied: executing>=1.2.0 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from stack-data->ipython->vibecheck) (2.1.0)
Requirement already satisfied: asttokens>=2.1.0 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from stack-data->ipython->vibecheck) (2.4.1)
Requirement already satisfied: pure-eval in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from stack-data->ipython->vibecheck) (0.2.3)
Requirement already satisfied: six>=1.12.0 in /home/bjzhu/libs/miniconda3/envs/pt2.51/lib/python3.12/site-packages (from asttokens>=2.1.0->stack-data->ipython->vibecheck) (1.16.0)
# Helper functionsDEVICE=torch.device("cuda:0")defimage_moments(image_batches,n_batches=None):"""
Compute mean and covariance of all pixels from batches of images
Args:
Image_batches: tuple
Image batches
n_batches: int
Number of Batch size
Returns:
m1: float
Mean of all pixels
cov: float
Covariance of all pixels
"""m1,m2=torch.zeros((),device=DEVICE),torch.zeros((),device=DEVICE)n=0forimintqdm(image_batches,total=n_batches,leave=False,desc="Computing pixel mean and covariance"):im=im.to(DEVICE)b=im.size()[0]im=im.view(b,-1)m1=m1+im.sum(dim=0)m2=m2+(im.view(b,-1,1)*im.view(b,1,-1)).sum(dim=0)n+=bm1,m2=m1/n,m2/ncov=m2-m1.view(-1,1)*m1.view(1,-1)returnm1.cpu(),cov.cpu()
definterpolate(A,B,num_interps):"""
Function to interpolate between images.
It does this by linearly interpolating between the
probability of each category you select and linearly
interpolating between the latent vector values.
Args:
A: list
List of categories
B: list
List of categories
num_interps: int
Quantity of pixel grids
Returns:
Interpolated np.ndarray
"""ifA.shape!=B.shape:raiseValueError("A and B must have the same shape")alphas=np.linspace(0,1,num_interps)returnnp.array([(1-a)*A+a*Bforainalphas])
defkl_q_p(zs,phi):"""
Compute the KL divergence KL(q||p).
Args:
zs: torch.tensor
Samples z drawn from q, shape [b, n, k].
phi: torch.tensor
Parameters of q, shape [b, k+1].
Returns:
torch.tensor
KL divergence estimate.
"""b,n,k=zs.size()mu_q,log_sig_q=phi[:,:-1],phi[:,-1]# Compute log probabilities for p(z) ~ N(0, 1)log_p=-0.5*(zs**2)# Compute log probabilities for q(z|phi)log_q=-0.5*((zs-mu_q.view(b,1,k))**2/log_sig_q.exp().view(b,1,1)**2)-log_sig_q.view(b,1,-1)# Compute KL divergencereturn(log_q-log_p).sum(dim=-1).mean()
deflog_p_x(x,mu_xs,sig_x):"""
Given [batch, ...] input x and [batch, n, ...] reconstructions, compute
pixel-wise log Gaussian probability Sum over pixel dimensions, but mean over batch and samples.
Args:
x: np.ndarray
Input Data
mu_xs: np.ndarray
Log of mean of samples
sig_x: np.ndarray
Log of standard deviation
Returns:
Mean over batch and samples.
"""b,n=mu_xs.size()[:2]# Flatten out pixels and add a singleton dimension [1] so that x will be# implicitly expanded when combined with mu_xsx=x.reshape(b,1,-1)_,_,p=x.size()squared_error=(x-mu_xs.view(b,n,-1))**2/(2*sig_x**2)# Size of squared_error is [b, n, p]. log prob is by definition sum over [p].# Expected value requires mean over [n].# Handling different size batches requires mean over [b].return-(squared_error+torch.log(sig_x)).sum(dim=2).mean(dim=(0,1))
defcout(x,layer):"""
Unnecessarily complicated but complete way to
calculate the output depth, height and width size for a Conv2D layer
Args:
x: tuple
Input size (depth, height, width)
layer: nn.Conv2d
The Conv2D layer
Returns:
Tuple of out-depth/out-height and out-width
Output shape as given in [Ref]
Ref: https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html
"""assertisinstance(layer,nn.Conv2d)p=layer.paddingifisinstance(layer.padding,tuple)else(layer.padding,)k=layer.kernel_sizeifisinstance(layer.kernel_size,tuple)else(layer.kernel_size,)d=layer.dilationifisinstance(layer.dilation,tuple)else(layer.dilation,)s=layer.strideifisinstance(layer.stride,tuple)else(layer.stride,)in_depth,in_height,in_width=xout_depth=layer.out_channelsout_height=1+(in_height+2*p[0]-(k[0]-1)*d[0]-1)//s[0]out_width=1+(in_width+2*p[-1]-(k[-1]-1)*d[-1]-1)//s[-1]return(out_depth,out_height,out_width)
defcout(x,layer):"""
Unnecessarily complicated but complete way to
calculate the output depth, height and width size for a Conv2D layer
Args:
x: tuple
Input size (depth, height, width)
layer: nn.Conv2d
The Conv2D layer
Returns:
Tuple of out-depth/out-height and out-width
Output shape as given in [Ref]
Ref: https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html
"""assertisinstance(layer,nn.Conv2d)p=layer.paddingifisinstance(layer.padding,tuple)else(layer.padding,)k=layer.kernel_sizeifisinstance(layer.kernel_size,tuple)else(layer.kernel_size,)d=layer.dilationifisinstance(layer.dilation,tuple)else(layer.dilation,)s=layer.strideifisinstance(layer.stride,tuple)else(layer.stride,)in_depth,in_height,in_width=xout_depth=layer.out_channelsout_height=1+(in_height+2*p[0]-(k[0]-1)*d[0]-1)//s[0]out_width=1+(in_width+2*p[-1]-(k[-1]-1)*d[-1]-1)//s[-1]return(out_depth,out_height,out_width)
defcout(x,layer):"""
Unnecessarily complicated but complete way to
calculate the output depth, height and width size for a Conv2D layer
Args:
x: tuple
Input size (depth, height, width)
layer: nn.Conv2d
The Conv2D layer
Returns:
Tuple of out-depth/out-height and out-width
Output shape as given in [Ref]
Ref: https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html
"""assertisinstance(layer,nn.Conv2d)p=layer.paddingifisinstance(layer.padding,tuple)else(layer.padding,)k=layer.kernel_sizeifisinstance(layer.kernel_size,tuple)else(layer.kernel_size,)d=layer.dilationifisinstance(layer.dilation,tuple)else(layer.dilation,)s=layer.strideifisinstance(layer.stride,tuple)else(layer.stride,)in_depth,in_height,in_width=xout_depth=layer.out_channelsout_height=1+(in_height+2*p[0]-(k[0]-1)*d[0]-1)//s[0]out_width=1+(in_width+2*p[-1]-(k[-1]-1)*d[-1]-1)//s[-1]return(out_depth,out_height,out_width)
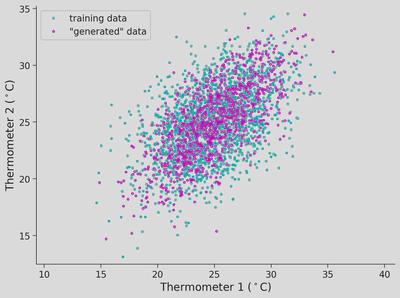
# @title Plotting functionsdefplot_gen_samples_ppca(therm1,therm2,therm_data_sim):"""
Plotting generated samples
Args:
therm1: list
Thermometer 1
therm2: list
Thermometer 2
therm_data_sim: list
Generated (simulate, draw) `n_samples` from pPCA model
Returns:
Nothing
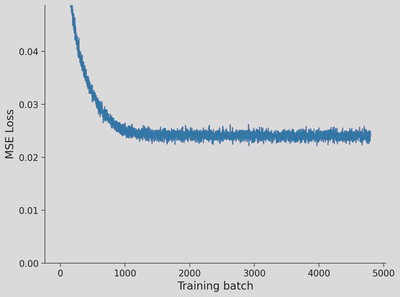
"""plt.plot(therm1,therm2,'.',c='c',label='training data')plt.plot(therm_data_sim[0],therm_data_sim[1],'.',c='m',label='"generated" data')plt.axis('equal')plt.xlabel(r'Thermometer 1 ($^\circ$C)')plt.ylabel(r'Thermometer 2 ($^\circ$C)')plt.legend()plt.show()defplot_linear_ae(lin_losses):"""
Plotting linear autoencoder
Args:
lin_losses: list
Log of linear autoencoder MSE losses
Returns:
Nothing
"""plt.figure()plt.plot(lin_losses)plt.ylim([0,2*torch.as_tensor(lin_losses).median()])plt.xlabel('Training batch')plt.ylabel('MSE Loss')plt.show()defplot_conv_ae(lin_losses,conv_losses):"""
Plotting convolutional autoencoder
Args:
lin_losses: list
Log of linear autoencoder MSE losses
conv_losses: list
Log of convolutional model MSE losses
Returns:
Nothing
"""plt.figure()plt.plot(lin_losses)plt.plot(conv_losses)plt.legend(['Lin AE','Conv AE'])plt.xlabel('Training batch')plt.ylabel('MSE Loss')plt.ylim([0,2*max(torch.as_tensor(conv_losses).median(),torch.as_tensor(lin_losses).median())])plt.show()defplot_images(images,h=3,w=3,plt_title=''):"""
Helper function to plot images
Args:
images: torch.tensor
Images
h: int
Image height
w: int
Image width
plt_title: string
Plot title
Returns:
Nothing
"""plt.figure(figsize=(h*2,w*2))plt.suptitle(plt_title,y=1.03)foriinrange(h*w):plt.subplot(h,w,i+1)plot_torch_image(images[i])plt.axis('off')plt.show()defplot_phi(phi,num=4):"""
Contour plot of relative entropy across samples
Args:
phi: list
Log of relative entropy changes
num: int
Number of iterations
"""plt.figure(figsize=(12,3))foriinrange(num):plt.subplot(1,num,i+1)plt.scatter(zs[i,:,0],zs[i,:,1],marker='.')th=torch.linspace(0,6.28318,100)x,y=torch.cos(th),torch.sin(th)# Draw 2-sigma contoursplt.plot(2*x*phi[i,2].exp().item()+phi[i,0].item(),2*y*phi[i,2].exp().item()+phi[i,1].item())plt.xlim(-5,5)plt.ylim(-5,5)plt.grid()plt.axis('equal')plt.suptitle('If rsample() is correct, then most but not all points should lie in the circles')plt.show()defplot_torch_image(image,ax=None):"""
Helper function to plot torch image
Args:
image: torch.tensor
Image
ax: plt object
If None, plt.gca()
Returns:
Nothing
"""ax=axifaxisnotNoneelseplt.gca()c,h,w=image.size()ifc==1:cm='gray'else:cm=None# Torch images have shape (channels, height, width)# but matplotlib expects# (height, width, channels) or just# (height, width) when grayscaleim_plt=torch.clip(image.detach().cpu().permute(1,2,0).squeeze(),0.0,1.0)ax.imshow(im_plt,cmap=cm)ax.set_xticks([])ax.set_yticks([])ax.spines['right'].set_visible(False)ax.spines['top'].set_visible(False)
# @title Set random seed# @markdown Executing `set_seed(seed=seed)` sets the random seed.# For deep learning, it's critical to set the random seed so that students can # have a baseline to compare their results to expected results.# Read more here: https://pytorch.org/docs/stable/notes/randomness.html# Call `set_seed` function in exercises to ensure reproducibility.importrandomimporttorchimportnumpyasnpdefset_seed(seed=None,seed_torch=True):"""
Function that controls randomness. NumPy and random modules must be imported.
Args:
seed : int, optional
A non-negative integer that defines the random state. Default is `None`.
seed_torch : bool, optional
If `True`, sets the random seed for PyTorch tensors. Default is `True`.
Returns:
None
"""ifseedisNone:seed=np.random.choice(2**32)random.seed(seed)np.random.seed(seed)ifseed_torch:torch.manual_seed(seed)torch.cuda.manual_seed_all(seed)torch.cuda.manual_seed(seed)torch.backends.cudnn.benchmark=Falsetorch.backends.cudnn.deterministic=Trueprint(f'Random seed {seed} has been set.')# In case that `DataLoader` is useddefseed_worker(worker_id):"""
DataLoader will reseed workers following randomness in
multi-process data loading algorithm.
Args:
worker_id : int
ID of subprocess to seed. `0` means that data will be loaded in
the main process.
Refer to: https://pytorch.org/docs/stable/data.html#data-loading-randomness
Returns:
None
"""worker_seed=torch.initial_seed()%2**32np.random.seed(worker_seed)random.seed(worker_seed)
defset_device():device="cuda"iftorch.cuda.is_available()else"cpu"ifdevice!="cuda":print("WARNING: Not running with GPU")else:print("GPU is enabled")returndevice
SEED=2021set_seed(seed=SEED)DEVICE=set_device()
Random seed 2021 has been set.
GPU is enabled
# @title Download `wordnet` dataset"""
NLTK Download Instructions:
To download `wordnet` using NLTK, run the following:
import nltk
nltk.download('wordnet')
"""importosimportrequestsimportzipfile# Set the environment variable for NLTK data directoryos.environ['NLTK_DATA']='nltk_data/'# Filenames and corresponding download URLsfnames=['wordnet.zip','omw-1.4.zip']urls=['https://osf.io/ekjxy/download','https://osf.io/kuwep/download']# Download and extract each fileforfname,urlinzip(fnames,urls):# Download the fileresponse=requests.get(url,allow_redirects=True)withopen(fname,'wb')asfile:file.write(response.content)# Extract the contents of the zip filewithzipfile.ZipFile(fname,'r')aszip_ref:zip_ref.extractall('nltk_data/corpora')print("WordNet dataset downloaded and extracted successfully.")
WordNet dataset downloaded and extracted successfully.
# @title Submit your feedbackcontent_review(f"{feedback_prefix}_Generative_Modeling_Video")
# @title Download BigGAN (a generative model) and a few standard image datasets# Initially, the model could be downloaded directly via:# biggan_model = BigGAN.from_pretrained('biggan-deep-256')importrequestsimporttorch# URL for the BigGAN modelurl="https://osf.io/3yvhw/download"# Filename for the downloaded modelfname="biggan_deep_256"# # Download the BigGAN model# response = requests.get(url, allow_redirects=True)# with open(fname, 'wb') as file:# file.write(response.content)# Load the downloaded BigGAN modelbiggan_model=torch.load(fname)print("BigGAN model downloaded and loaded successfully.")
/tmp/ipykernel_42455/2836300935.py:20: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
biggan_model = torch.load(fname)
BigGAN model downloaded and loaded successfully.
!pipinstallnltk--quiet# @title BigGAN Image Generator (updates may take a few seconds, please be patient)fromscipy.statsimporttruncnormimporttorchimportnumpyasnpimportmatplotlib.pyplotaspltfromipywidgetsimportFloatSlider,Dropdown,VBox,interactive_output,Layoutdeftruncated_noise_sample(batch_size=1,dim_z=128,truncation=1.0,seed=None):"""
Create a truncated noise vector.
Args:
batch_size (int): Number of samples to generate.
dim_z (int): Dimension of the latent vector z.
truncation (float): Truncation value to control the range of z.
seed (int, optional): Seed for the random generator.
Returns:
np.ndarray: Array of shape (batch_size, dim_z) with truncated noise values.
"""state=NoneifseedisNoneelsenp.random.RandomState(seed)values=truncnorm.rvs(-2,2,size=(batch_size,dim_z),random_state=state).astype(np.float32)returntruncation*valuesdefsample_from_biggan(category,z_magnitude):"""
Sample images from BigGAN Image Generator.
Args:
category (str): Selected category label.
z_magnitude (float): Magnitude of variation vector (truncation value).
Returns:
None
"""truncation=z_magnitudez=truncated_noise_sample(truncation=truncation,batch_size=4)y=one_hot_from_names(category,batch_size=4)# Convert to tensorsz=torch.from_numpy(z).float()y=torch.from_numpy(y)# Move tensors and model to GPUdevice=set_device()z=z.to(device)y=y.to(device)biggan_model.to(device)# Generate imageswithtorch.no_grad():output=biggan_model(z,y,truncation)# Process the output to [0, 1] rangeoutput=output.to('cpu')output=torch.clip(((output.detach().clone()+1)/2.0),0,1)# Plot the generated imagesfig,axes=plt.subplots(2,2,figsize=(8,8))axes=axes.flatten()foriinrange(4):axes[i].imshow(output[i].squeeze().permute(1,2,0))axes[i].axis('off')plt.show()# UI Widgets for interactive controlz_slider=FloatSlider(min=0.1,max=1.0,step=0.1,value=0.1,continuous_update=False,description='Truncation Value',style={'description_width':'100px'},layout=Layout(width='440px'))category_dropdown=Dropdown(options=['tench','magpie','jellyfish','German shepherd','bee','acoustic guitar','coffee mug','minibus','monitor'],value="German shepherd",description="Category:")widgets_ui=VBox([category_dropdown,z_slider])# Bind the UI widgets to the functionwidgets_out=interactive_output(sample_from_biggan,{'z_magnitude':z_slider,'category':category_dropdown})# Display the widgets and outputdisplay(widgets_ui,widgets_out)
# @markdown BigGAN Interpolation Widget (the updates may take a few seconds)definterpolate_biggan(category_A,category_B):"""
Interpolation function with BigGan
Args:
category_A: string
Category specification
category_B: string
Category specification
Returns:
Nothing
"""num_interps=16# category_A = 'jellyfish' #@param ['tench', 'magpie', 'jellyfish', 'German shepherd', 'bee', 'acoustic guitar', 'coffee mug', 'minibus', 'monitor']# z_magnitude_A = 0 #@param {type:"slider", min:-10, max:10, step:1}# category_B = 'German shepherd' #@param ['tench', 'magpie', 'jellyfish', 'German shepherd', 'bee', 'acoustic guitar', 'coffee mug', 'minibus', 'monitor']# z_magnitude_B = 0 #@param {type:"slider", min:-10, max:10, step:1}definterpolate_and_shape(A,B,num_interps):"""
Function to interpolate and shape images.
It does this by linearly interpolating between the
probability of each category you select and linearly
interpolating between the latent vector values.
Args:
A: list
List of categories
B: list
List of categories
num_interps: int
Quantity of pixel grids
Returns:
Interpolated np.ndarray
"""interps=interpolate(A,B,num_interps)return(interps.transpose(1,0,*range(2,len(interps.shape))).reshape(num_interps,*interps.shape[2:]))# unit_vector = np.ones((1, 128))/np.sqrt(128)# z_A = z_magnitude_A * unit_vector# z_B = z_magnitude_B * unit_vectortruncation=.4z_A=truncated_noise_sample(truncation=truncation,batch_size=1)z_B=truncated_noise_sample(truncation=truncation,batch_size=1)y_A=one_hot_from_names(category_A,batch_size=1)y_B=one_hot_from_names(category_B,batch_size=1)z_interp=interpolate_and_shape(z_A,z_B,num_interps)y_interp=interpolate_and_shape(y_A,y_B,num_interps)# Convert to tensorz_interp=torch.from_numpy(z_interp).float()y_interp=torch.from_numpy(y_interp).float()# Move to GPUz_interp=z_interp.to(DEVICE)y_interp=y_interp.to(DEVICE)biggan_model.to(DEVICE)withtorch.no_grad():output=biggan_model(z_interp,y_interp,1)# Back to CPUoutput=output.to('cpu')# The output layer of BigGAN has a tanh layer,# resulting the range of [-1, 1] for the output image# Therefore, we normalize the images properly to# [0, 1] range.# Clipping is only in case of numerical instability# problemsoutput=torch.clip(((output.detach().clone()+1)/2.0),0,1)output=output# Make grid and show generated samplesoutput_grid=torchvision.utils.make_grid(output,nrow=min(4,output.shape[0]),padding=5)plt.axis('off');plt.imshow(output_grid.permute(1,2,0))plt.show()# z_A_slider = IntSlider(min=-10, max=10, step=1, value=0,# continuous_update=False, description='Z Magnitude A',# layout=Layout(width='440px'),# style={'description_width': 'initial'})# z_B_slider = IntSlider(min=-10, max=10, step=1, value=0,# continuous_update=False, description='Z Magntude B',# layout=Layout(width='440px'),# style={'description_width': 'initial'})category_A_dropdown=Dropdown(options=['tench','magpie','jellyfish','German shepherd','bee','acoustic guitar','coffee mug','minibus','monitor'],value="German shepherd",description="Category A: ")category_B_dropdown=Dropdown(options=['tench','magpie','jellyfish','German shepherd','bee','acoustic guitar','coffee mug','minibus','monitor'],value="jellyfish",description="Category B: ")widgets_ui=VBox([HBox([category_A_dropdown]),HBox([category_B_dropdown])])widgets_out=interactive_output(interpolate_biggan,{'category_A':category_A_dropdown,# 'z_magnitude_A': z_A_slider,'category_B':category_B_dropdown})# 'z_magnitude_B': z_B_slider})display(widgets_ui,widgets_out)
defgenerate_data(n_samples,mean_of_temps,cov_of_temps,seed):"""
Generate random data, normally distributed
Args:
n_samples : int
The number of samples to be generated
mean_of_temps : numpy.ndarray
1D array with the mean of temparatures, Kx1
cov_of_temps : numpy.ndarray
2D array with the covariance, KxK
seed : int
Set random seed for the pseudo random generator
Returns:
therm1 : numpy.ndarray
Thermometer 1
therm2 : numpy.ndarray
Thermometer 2
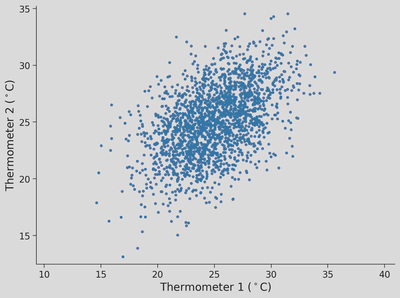
"""np.random.seed(seed)therm1,therm2=np.random.multivariate_normal(mean_of_temps,cov_of_temps,n_samples).Treturntherm1,therm2n_samples=2000mean_of_temps=np.array([25,25])cov_of_temps=np.array([[10,5],[5,10]])therm1,therm2=generate_data(n_samples,mean_of_temps,cov_of_temps,seed=SEED)plt.plot(therm1,therm2,'.')plt.axis('equal')plt.xlabel('Thermometer 1 ($^\\circ$C)')plt.ylabel('Thermometer 2 ($^\\circ$C)')plt.show()
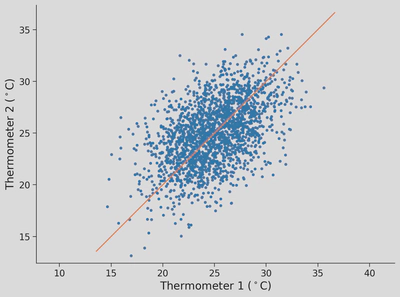
# @markdown Add first PC axes to the plotplt.plot(therm1,therm2,'.')plt.axis('equal')plt.xlabel('Thermometer 1 ($^\\circ$C)')plt.ylabel('Thermometer 2 ($^\\circ$C)')plt.plot([plt.axis()[0],plt.axis()[1]],[plt.axis()[0],plt.axis()[1]])plt.show()
# Project Data onto the principal component axes.# We could have "learned" this from the data by applying PCA,# but we "know" the value from the problem definition.pc_axes=np.array([1.0,1.0])/np.sqrt(2.0)# Thermometers datatherm_data=np.array([therm1,therm2])# Zero center the datatherm_data_mean=np.mean(therm_data,1)therm_data_center=np.outer(therm_data_mean,np.ones(therm_data.shape[1]))therm_data_zero_centered=therm_data-therm_data_center# Calculate the variance of the projection on the PC axespc_projection=np.matmul(pc_axes,therm_data_zero_centered)pc_axes_variance=np.var(pc_projection)# Calculate the residual variance (variance not accounted for by projection on the PC axes)sensor_noise_std=np.mean(np.linalg.norm(therm_data_zero_centered-np.outer(pc_axes,pc_projection),axis=0,ord=2))sensor_noise_var=sensor_noise_std**2
defgen_from_pPCA(noise_var,data_mean,pc_axes,pc_variance):"""
Generate samples from pPCA
Args:
noise_var: np.ndarray
Sensor noise variance
data_mean: np.ndarray
Thermometer data mean
pc_axes: np.ndarray
Principal component axes
pc_variance: np.ndarray
The variance of the projection on the PC axes
Returns:
therm_data_sim: np.ndarray
Generated (simulate, draw) `n_samples` from pPCA model
"""# We are matching this value to the thermometer data so the visualizations look similarn_samples=1000# Randomly sample from z (latent space value)z=np.random.normal(0.0,np.sqrt(pc_variance),n_samples)# Sensor noise covariance matrix (∑)epsilon_cov=[[noise_var,0.0],[0.0,noise_var]]# Data mean reshaped for the generationsim_mean=np.outer(data_mean,np.ones(n_samples))# Draw `n_samples` from `np.random.multivariate_normal`rand_eps=np.random.multivariate_normal([0.0,0.0],epsilon_cov,n_samples)rand_eps=rand_eps.T# Generate (simulate, draw) `n_samples` from pPCA modeltherm_data_sim=sim_mean+np.outer(pc_axes,z)+rand_epsreturntherm_data_sim## Uncomment to test your codetherm_data_sim=gen_from_pPCA(sensor_noise_var,therm_data_mean,pc_axes,pc_axes_variance)plot_gen_samples_ppca(therm1,therm2,therm_data_sim)
Autoencoders
# @markdown Download MNIST and CIFAR10 datasetsimporttarfile,requests,osfname='MNIST.tar.gz'name='mnist'url='https://osf.io/y2fj6/download'ifnotos.path.exists(name):print('\nDownloading MNIST dataset...')r=requests.get(url,allow_redirects=True)withopen(fname,'wb')asfh:fh.write(r.content)print('\nDownloading MNIST completed!\n')ifnotos.path.exists(name):withtarfile.open(fname)astar:tar.extractall(name,filter=None)os.remove(fname)else:print('MNIST dataset has been downloaded.\n')fname='cifar-10-python.tar.gz'name='cifar10'url='https://osf.io/jbpme/download'ifnotos.path.exists(name):print('\nDownloading CIFAR10 dataset...')r=requests.get(url,allow_redirects=True)withopen(fname,'wb')asfh:fh.write(r.content)print('\nDownloading CIFAR10 completed!')ifnotos.path.exists(name):withtarfile.open(fname)astar:tar.extractall(name,filter=None)os.remove(fname)else:print('CIFAR10 dataset has been downloaded.')
MNIST dataset has been downloaded.
CIFAR10 dataset has been downloaded.
# @markdown Load MNIST and CIFAR10 image datasets# See https://pytorch.org/docs/stable/torchvision/datasets.html# MNISTmnist=datasets.MNIST('./mnist/',train=True,transform=transforms.ToTensor(),download=False)mnist_val=datasets.MNIST('./mnist/',train=False,transform=transforms.ToTensor(),download=False)# CIFAR 10cifar10=datasets.CIFAR10('./cifar10/',train=True,transform=transforms.ToTensor(),download=False)cifar10_val=datasets.CIFAR10('./cifar10/',train=False,transform=transforms.ToTensor(),download=False)
# @markdown Execute this cell to enable helper function `get_data`defget_data(name='mnist'):"""
Get data
Args:
name: string
Name of the dataset
Returns:
my_dataset: dataset instance
Instance of dataset
my_dataset_name: string
Name of the dataset
my_dataset_shape: tuple
Shape of dataset
my_dataset_size: int
Size of dataset
my_valset: torch.loader
Validation loader
"""ifname=='mnist':my_dataset_name="MNIST"my_dataset=mnistmy_valset=mnist_valmy_dataset_shape=(1,28,28)my_dataset_size=28*28elifname=='cifar10':my_dataset_name="CIFAR10"my_dataset=cifar10my_valset=cifar10_valmy_dataset_shape=(3,32,32)my_dataset_size=3*32*32returnmy_dataset,my_dataset_name,my_dataset_shape,my_dataset_size,my_valset
# @markdown #### Run to define the `train_autoencoder` function.# @markdown Feel free to inspect the training function if the time allows.# @markdown `train_autoencoder(autoencoder, dataset, device, epochs=20, batch_size=250, seed=0)`deftrain_autoencoder(autoencoder,dataset,device,epochs=20,batch_size=250,seed=0):"""
Function to train autoencoder
Args:
autoencoder: nn.module
Autoencoder instance
dataset: function
Dataset
device: string
GPU if available. CPU otherwise
epochs: int
Number of epochs [default: 20]
batch_size: int
Batch size
seed: int
Set seed for reproducibility; [default: 0]
Returns:
mse_loss: float
MSE Loss
"""autoencoder.to(device)optim=torch.optim.Adam(autoencoder.parameters(),lr=1e-3,weight_decay=1e-5)loss_fn=nn.MSELoss()g_seed=torch.Generator()g_seed.manual_seed(seed)loader=DataLoader(dataset,batch_size=batch_size,shuffle=True,pin_memory=True,num_workers=2,worker_init_fn=seed_worker,generator=g_seed)mse_loss=torch.zeros(epochs*len(dataset)//batch_size,device=device)i=0forepochintrange(epochs,desc='Epoch'):forim_batch,_inloader:im_batch=im_batch.to(device)optim.zero_grad()reconstruction=autoencoder(im_batch)# Loss calculationloss=loss_fn(reconstruction.view(batch_size,-1),target=im_batch.view(batch_size,-1))loss.backward()optim.step()mse_loss[i]=loss.detach()i+=1# After training completes,# make sure the model is on CPU so we can easily# do more visualizations and demos.autoencoder.to('cpu')returnmse_loss.cpu()
dataset_name='mnist'# This can be mnist or cifar10train_set,dataset_name,data_shape,data_size,valid_set=get_data(name=dataset_name)# Pick your own KK=20set_seed(seed=SEED)## Uncomment to test your codelin_ae=LinearAutoEncoder(data_size,K)lin_losses=train_autoencoder(lin_ae,train_set,device=DEVICE,seed=SEED)plot_linear_ae(lin_losses)
Random seed 2021 has been set.
Epoch: 0%| | 0/20 [00:00<?, ?it/s]
# PCA requires finding the top K eigenvectors of the data covariance. Start by# finding the mean and covariance of the pixels in our datasetg_seed=torch.Generator()g_seed.manual_seed(SEED)loader=DataLoader(train_set,batch_size=32,pin_memory=True,num_workers=2,worker_init_fn=seed_worker,generator=g_seed)mu,cov=image_moments((imforim,_inloader),n_batches=len(train_set)//32)pca_encode,pca_decode=pca_encoder_decoder(mu,cov,K)
Computing pixel mean and covariance: 0%| | 0/1875 [00:00<?, ?it/s]
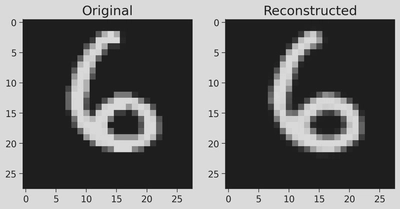
# @markdown Visualize the reconstructions $\mathbf{x}'$, run this code a few times to see different examples.n_plot=7plt.figure(figsize=(10,4.5))foriinrange(n_plot):idx=torch.randint(len(train_set),size=())image,_=train_set[idx]# Get reconstructed image from autoencoderwithtorch.no_grad():reconstruction=lin_ae(image.unsqueeze(0)).reshape(image.size())# Get reconstruction from PCA dimensionality reductionh_pca=pca_encode(image)recon_pca=pca_decode(h_pca).reshape(image.size())plt.subplot(3,n_plot,i+1)plot_torch_image(image)ifi==0:plt.ylabel('Original\nImage')plt.subplot(3,n_plot,i+1+n_plot)plot_torch_image(reconstruction)ifi==0:plt.ylabel(f'Lin AE\n(K={K})')plt.subplot(3,n_plot,i+1+2*n_plot)plot_torch_image(recon_pca)ifi==0:plt.ylabel(f'PCA\n(K={K})')plt.show()
dummy_image=torch.rand(data_shape).unsqueeze(0)in_channels=data_shape[0]out_channels=7dummy_conv=nn.Conv2d(in_channels=in_channels,out_channels=out_channels,kernel_size=5)dummy_deconv=nn.ConvTranspose2d(in_channels=out_channels,out_channels=in_channels,kernel_size=5)print(f'Size of image is {dummy_image.shape}')print(f'Size of Conv2D(image) {dummy_conv(dummy_image).shape}')print(f'Size of ConvTranspose2D(Conv2D(image)) {dummy_deconv(dummy_conv(dummy_image)).shape}')
Size of image is torch.Size([1, 1, 28, 28])
Size of Conv2D(image) torch.Size([1, 7, 24, 24])
Size of ConvTranspose2D(Conv2D(image)) torch.Size([1, 1, 28, 28])
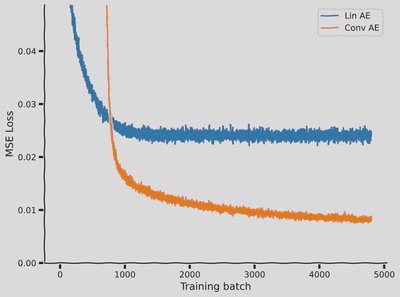
set_seed(seed=SEED)## Uncomment to test your solutiontrained_conv_AE=ConvAutoEncoder(data_shape,K)asserttrained_conv_AE.encode(train_set[0][0].unsqueeze(0)).numel()==K,"Encoder output size should be K!"conv_losses=train_autoencoder(trained_conv_AE,train_set,device=DEVICE,seed=SEED)withplt.xkcd():plot_conv_ae(lin_losses,conv_losses)
Random seed 2021 has been set.
Epoch: 0%| | 0/20 [00:00<?, ?it/s]
# @markdown Visualize the linear and nonlinear AE outputsiflin_ae.enc_lin.out_features!=trained_conv_AE.enc_lin.out_features:raiseValueError('ERROR: your linear and convolutional autoencoders have different values of K')n_plot=7plt.figure(figsize=(10,4.5))foriinrange(n_plot):idx=torch.randint(len(train_set),size=())image,_=train_set[idx]withtorch.no_grad():# Get reconstructed image from linear autoencoderlin_recon=lin_ae(image.unsqueeze(0))[0]# Get reconstruction from deep (nonlinear) autoencodernonlin_recon=trained_conv_AE(image.unsqueeze(0))[0]plt.subplot(3,n_plot,i+1)plot_torch_image(image)ifi==0:plt.ylabel('Original\nImage')plt.subplot(3,n_plot,i+1+n_plot)plot_torch_image(lin_recon)ifi==0:plt.ylabel(f'Lin AE\n(K={K})')plt.subplot(3,n_plot,i+1+2*n_plot)plot_torch_image(nonlin_recon)ifi==0:plt.ylabel(f'NonLin AE\n(K={K})')plt.show()
# @markdown Train a VAE for MNIST while watching the video.# (Note: this VAE has a 2D latent space. If you are feeling ambitious,# edit the code and modify the latent space dimensionality and see what happens.)K_VAE=2classConvVAE(nn.Module):"""
Convolutional Variational Autoencoder
"""def__init__(self,K,num_filters=32,filter_size=5):"""
Initialize parameters of ConvVAE
Args:
K: int
Bottleneck dimensionality
num_filters: int
Number of filters [default: 32]
filter_size: int
Filter size [default: 5]
Returns:
Nothing
"""super(ConvVAE,self).__init__()# With padding=0, calculate pixel reduction per Conv2D/ConvTranspose2D layerfilter_reduction=2*(filter_size//2)# Calculate shape after two Conv2D layersself.shape_after_conv=(num_filters,data_shape[1]-2*filter_reduction,data_shape[2]-2*filter_reduction)flat_size_after_conv=(self.shape_after_conv[0]*self.shape_after_conv[1]*self.shape_after_conv[2])# Define the encoder (recognition model)self.q_bias=BiasLayer(data_shape)self.q_conv_1=nn.Conv2d(data_shape[0],num_filters,5)self.q_conv_2=nn.Conv2d(num_filters,num_filters,5)self.q_flatten=nn.Flatten()# K for mu, 1 for log_sigself.q_fc_phi=nn.Linear(flat_size_after_conv,K+1)# Define the decoder (generative model)self.p_fc_upsample=nn.Linear(K,flat_size_after_conv)self.p_unflatten=nn.Unflatten(-1,self.shape_after_conv)self.p_deconv_1=nn.ConvTranspose2d(num_filters,num_filters,5)self.p_deconv_2=nn.ConvTranspose2d(num_filters,data_shape[0],5)self.p_bias=BiasLayer(data_shape)# Parameter for learning scalar sigma_x for all pixelsself.log_sig_x=nn.Parameter(torch.zeros(()))definfer(self,x):"""
Map x to phi for latent space sampling
Args:
x: torch.tensor
Input features
Returns:
phi: torch.tensor
Latent space parameters
"""s=self.q_bias(x)s=F.relu(self.q_conv_1(s))s=F.relu(self.q_conv_2(s))flat_s=s.view(s.size()[0],-1)phi=self.q_fc_phi(flat_s)returnphidefgenerate(self,zs):"""
Generate images from latent samples
Args:
zs: torch.tensor
Latent samples
Returns:
mu_xs: torch.tensor
Generated images
"""b,n,k=zs.size()s=zs.view(b*n,-1)s=F.relu(self.p_fc_upsample(s)).view((b*n,)+self.shape_after_conv)s=F.relu(self.p_deconv_1(s))s=self.p_deconv_2(s)s=self.p_bias(s)mu_xs=s.view(b,n,-1)returnmu_xsdefdecode(self,zs):"""
Decoder for compatibility with conv-AE code
Args:
zs: torch.tensor
Latent samples
Returns:
torch.tensor
Decoded images
"""returnself.generate(zs.unsqueeze(0))defforward(self,x):"""
Forward pass
Args:
x: torch.tensor
Input image
Returns:
torch.tensor
Reconstructed image
"""phi=self.infer(x)zs=rsample(phi,1)returnself.generate(zs).view(x.size())defelbo(self,x,n=1):"""
Compute the Evidence Lower Bound (ELBO)
Args:
x: torch.tensor
Input image
n: int
Number of latent samples
Returns:
torch.tensor
ELBO value
"""phi=self.infer(x)zs=rsample(phi,n)mu_xs=self.generate(zs)returnlog_p_x(x,mu_xs,self.log_sig_x.exp())-kl_q_p(zs,phi)defrsample(phi,n_samples):"""
Reparameterization trick for latent sampling
Args:
phi: torch.tensor
Latent space parameters
n_samples: int
Number of samples
Returns:
torch.tensor
Latent samples
"""b,kplus1=phi.size()k=kplus1-1mu,sig=phi[:,:-1],phi[:,-1].exp()eps=torch.randn(b,n_samples,k,device=phi.device)returneps*sig.view(b,1,1)+mu.view(b,1,k)deftrain_vae(vae,dataset,epochs=10,n_samples=1000):"""
Train a Variational Autoencoder (VAE)
Args:
vae: nn.Module
VAE model
dataset: torch.utils.data.Dataset
Dataset
epochs: int
Number of training epochs
n_samples: int
Number of latent samples
Returns:
elbo_vals: list
ELBO values during training
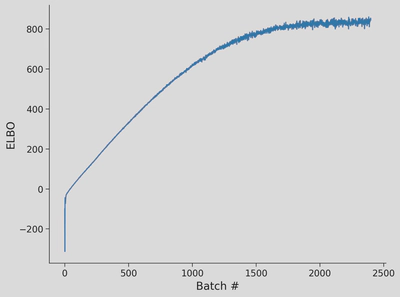
"""opt=torch.optim.Adam(vae.parameters(),lr=1e-3,weight_decay=0)elbo_vals=[]vae.to(DEVICE)vae.train()loader=DataLoader(dataset,batch_size=250,shuffle=True,pin_memory=True)forepochintrange(epochs,desc='Epochs'):forim,_intqdm(loader,total=len(dataset)//250,desc='Batches',leave=False):im=im.to(DEVICE)opt.zero_grad()loss=-vae.elbo(im)loss.backward()opt.step()elbo_vals.append(-loss.item())vae.to('cpu')vae.eval()returnelbo_valstrained_conv_VarAE=ConvVAE(K=K_VAE)elbo_vals=train_vae(trained_conv_VarAE,train_set,n_samples=10000)print(f'Learned sigma_x is {torch.exp(trained_conv_VarAE.log_sig_x)}')# Uncomment below if you'd like to see the training curve of the ELBO loss functionplt.figure()plt.plot(elbo_vals)plt.xlabel('Batch #')plt.ylabel('ELBO')plt.show()
## generating images from above VAEdefgenerate_images(autoencoder,K,n_images=1):output_shape=(n_images,)+data_shapewithtorch.no_grad():# Sample z from a unit gaussian, pass through autoencoder.decode()z=torch.randn(n_images,K)x=autoencoder.decode(z)returnx.reshape(output_shape)set_seed(seed=SEED)## Uncomment to test your solutionimages=generate_images(trained_conv_AE,K,n_images=9)plot_images(images,plt_title='Images Generated from the Conv-AE')images=generate_images(trained_conv_VarAE,K_VAE,n_images=9)plot_images(images,plt_title='Images Generated from a Conv-Variational-AE')
device="cuda"iftorch.cuda.is_available()else"cpu"# Model parametersinput_dim=1# MNIST has 1 channelembedding_dim=16# Smaller latent dimensionnum_embeddings=256# Smaller dictionary size# Initialize model and optimizervqvae=VQVAE(input_dim,embedding_dim,num_embeddings).to(device)optimizer=torch.optim.Adam(vqvae.parameters(),lr=1e-3)# Train the modeltrain_vqvae(vqvae,train_loader,optimizer,epochs=20)
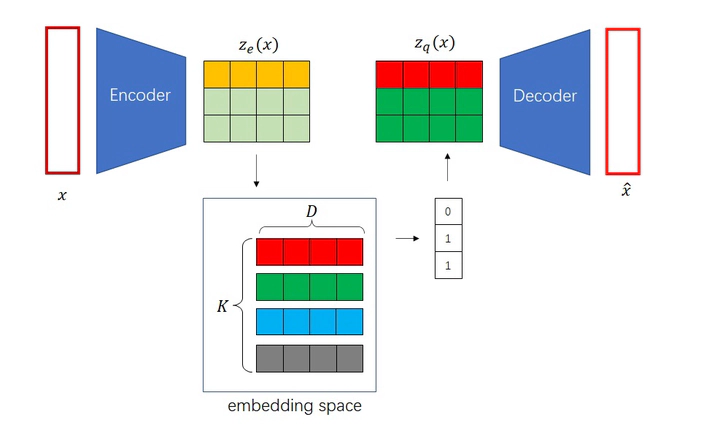 Image credit: Unsplash
Image credit: Unsplash